
A Tool for Demographers and Social Scientists to Categorize Open-Ended Survey Data: CatLLM
Published:

We built a tool for demographers and social scientists who want to make sense of open-ended survey responses.
This Python package, called CatLLM, gives social scientists a few main features:
- Extract categories from a corpus of survey responses or text.
- Sort responses/text into categories
- Assign multiple categories to images
Key Features
- Enter your list of categories and your survey answers and the package outputs categories.
- The output is always organized and reliable and ready to plug into statistical models.
- Relies on the latest “promp engineering” techniques.
- Compatible with OpenAI, Anthropic, Mistral, and Perplexity (Llama) models.
- Skips over any missing survey answers so you don’t waste money on unnecessary API calls.
- If your system crashes, your work is safe—no lost progress.
- The package double-checks that you entered the categories you wanted.
- Offers both single-category and multi-category sorting options.
Beta Test Results
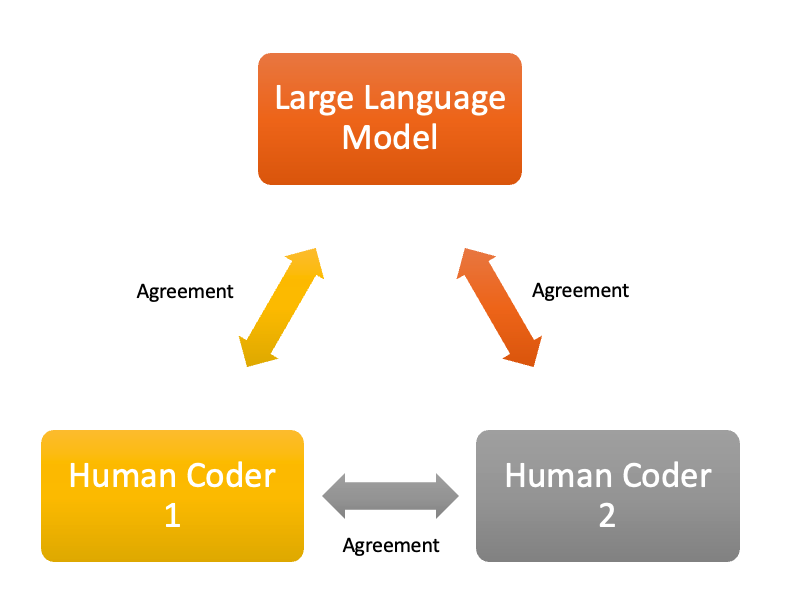
The following results, along with others I will publish soon, show that large language models (LLMs) are practical tools for data categorization—even for social scientists who need high accuracy.
Jake Derr, a data scientist at UC Berkeley, helped us test CatLLM. We used a set of real job categories (based on official government codes) and ran the tool on 6,399 survey responses. The process took about about 4 hours (236 minutes) and cost around $12. For comparison, Jake manually sorted the same data in about 20 hours.
The tool’s results matched Jake’s choices most of the time. They disagreed on about 8.8% of the answers, which is similar to the kind of disagreement you’d expect between two people doing the same task. Most of these differences were due to reasonable differences in interpretation, not mistakes. Sometimes, either the model or Jake made a small error.
During testing, we (I) accidentally entered 23 categories instead of 24 (missed a comma!). To prevent this in the future, we added a feature that asks users to double-check their category list.
Overall, CatLLM helped us sort survey responses faster and more efficiently—without needing to hire a third person to double-check everything. We used the model as a “quality assurance tool,” after which Jake ended up changing a signficant proportion of his assigned categories. In the end, the model and Jake agreed 96% of the time.
While CatLLM and similar large language model tools can greatly speed up and reduce the cost of annotation—sometimes by a factor of 30 or more compared to traditional human annotation—they are not meant to replace the valuable work of human annotators like Jake. Research shows that while LLMs can outperform crowd workers on some tasks and offer substantial cost savings, there are still cases where human expertise is essential, especially for ambiguous or complex data points. The best results come from combining the speed and efficiency of LLMs with human oversight, ensuring high-quality, reliable annotations.
Next, we’ll review the answers where Jake and the model disagreed. We’ll talk through each case and make a final decision together. Human judgment always comes first: if there’s a disagreement, we discuss it and go with the human’s choice.
We tested the function llm_extract_multi_class which assigns categories to your entire corpus with just four lines of code:
pip install cat-llm
import catllm as cat
jobs_categorized = cat.multi_class(
survey_question = job_question,
survey_input = jobs['Response'],
categories = job_categories)
Examples of Disagreements Between the Model and Jake
Here are a few examples where CatLLM and Jake categorized the same job title differently:
- “Creative Lead”
- Jake: Computer and Mathematical Occupations
- Model: Arts, Design, Entertainment, Sports, and Media Occupations
- “Analyst”
- Jake: Life, Physical, and Social Science Occupations
- Model: Business and Financial Occupations
- “Circuit Design”
- Jake: Architecture and Engineering Occupations
- Model: Computer and Mathematical Occupations
- “Server”
- Jake: Food Preparation and Serving Related Occupations
- Model: Sales and Related Occupations
- “Program Management”
- Jake: Computer and Mathematical Occupations
- Model: Management Occupations
- “Workforce Coordinator”
- Jake: Business and Financial Operations Occupations
- Model: Management Occupations
- “Vet SEC”
- This one was tricky. “Vet SEC” is actually a security company.
- Jake: Healthcare Practitioners and Technical Occupations (he thought it was related to veterinary care)
- Model: Marked three categories, including the correct one: Protective Services. It also selected “Unclear” because it wasn’t sure.
- This one was tricky. “Vet SEC” is actually a security company.
- “External vendor management”
- Jake: Sales and Related Occupations
- Model: Business and Financial Operations Occupations
- “Order support”
- Jake: Transportation and Material Moving Occupations
- Model: Office and Administrative Support Occupations
- “Public Policy Specialist”
- Jake: Business and Financial Operations Occupations
- Model: Life, Physical, and Social Science Occupations
These examples show that even with clear job titles, people and models can interpret them differently. Most disagreements were reasonable and highlight the importance of human review in the final decision process.
###References:
Soria, C. (2025). CatLLM (0.0.8). Zenodo. https://doi.org/10.5281/zenodo.15532317


